Microsoft Fabric and Azure
Written By: Sajagan Thirugnanam and Austin Levine
Last Updated on October 2, 2025
If you’re leading data or finance in a mid-to-large enterprise, Fabric gives you two mainstream ways to land and transform data at scale: Dataflows Gen2 (Power Query in the Fabric Data Factory experience) and Notebooks (Spark in the Data Engineering experience). Both land data into OneLake and can power Lakehouse/Warehouse models. The practical question is less “which is better?” and more “which is right for this workload, and when do we switch?”
Quick answer: Use Dataflows Gen2 by default for structured sources and ELT patterns where transformations can be pushed down to the source (query folding) and where incremental loads keep the footprint manageable. Use Notebooks when transformations can’t fold, you need distributed compute (large joins/aggregations), work with nested files or streaming, require advanced data engineering libraries, or need Delta-level maintenance at scale.
Table of contents
How it works
Decision guide: Dataflows Gen2 vs. Notebooks
Are Dataflows still efficient for very large tables?
When are Notebooks mandatory?
Implementation guide
Performance, capacity, and cost tactics
Governance and security considerations
Common pitfalls
FAQs
Glossary
Closing
How it works
Dataflows Gen2 run Power Query in the cloud to extract and transform data from hundreds of sources, and then land the result to Lakehouse Tables (Delta), Lakehouse Files (preview), or a Fabric Warehouse. Their strength is source connectivity, productivity, and the ability to push work back to the source system via query folding. They run on your Fabric capacity and are orchestrated in the Data Factory experience.
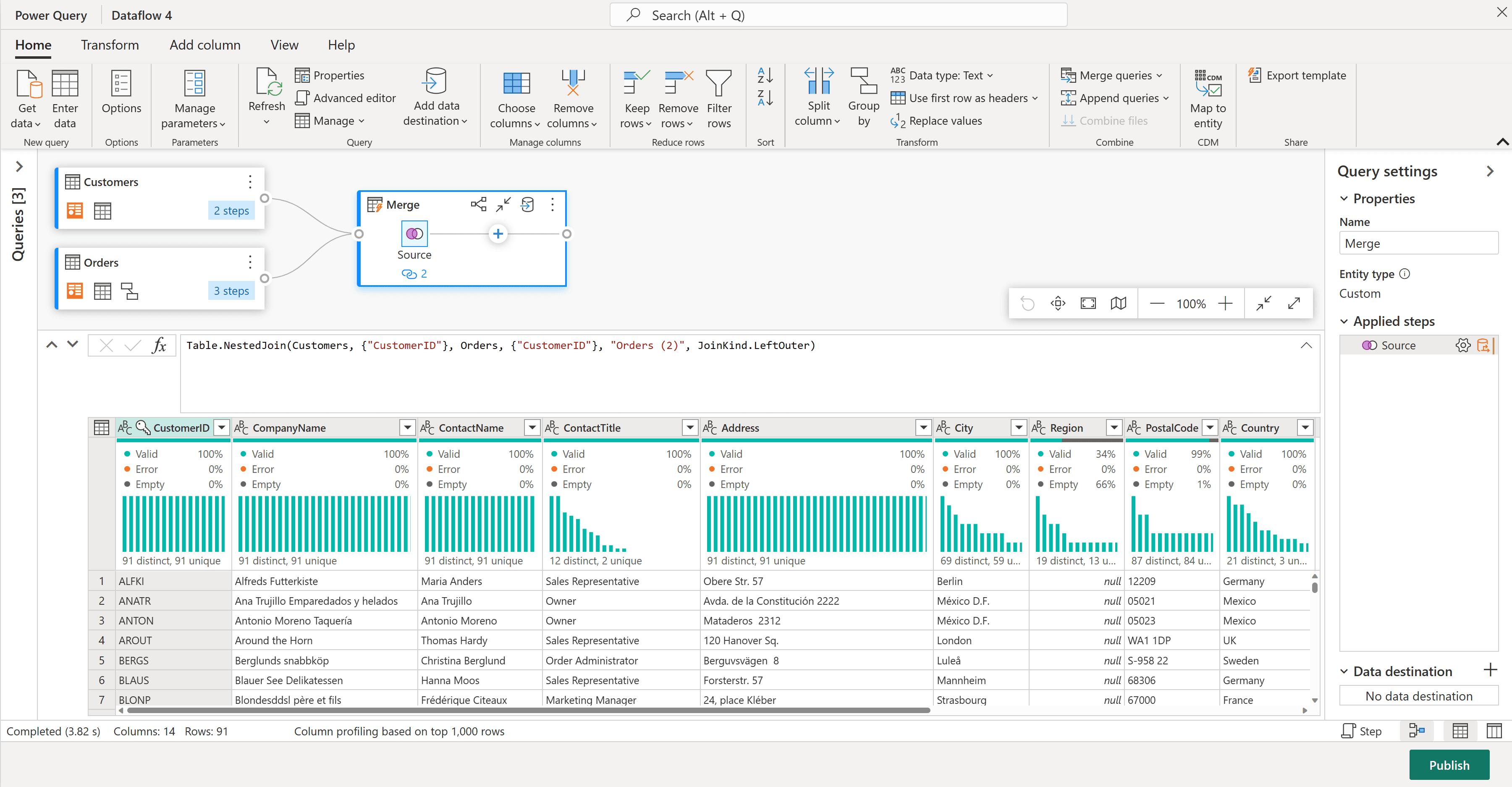
Credit: Microsoft
Notebooks in Fabric run on managed Apache Spark. You write transformations in Python (PySpark), Spark SQL, Scala, or R (SparkR) and operate directly against files and Delta tables in OneLake. The engine is distributed, so joins, wide aggregations, and complex transformations scale out across the Spark cluster. Notebooks also cover scenarios beyond pure ETL: data quality frameworks, feature engineering, and streaming/micro-batch patterns.
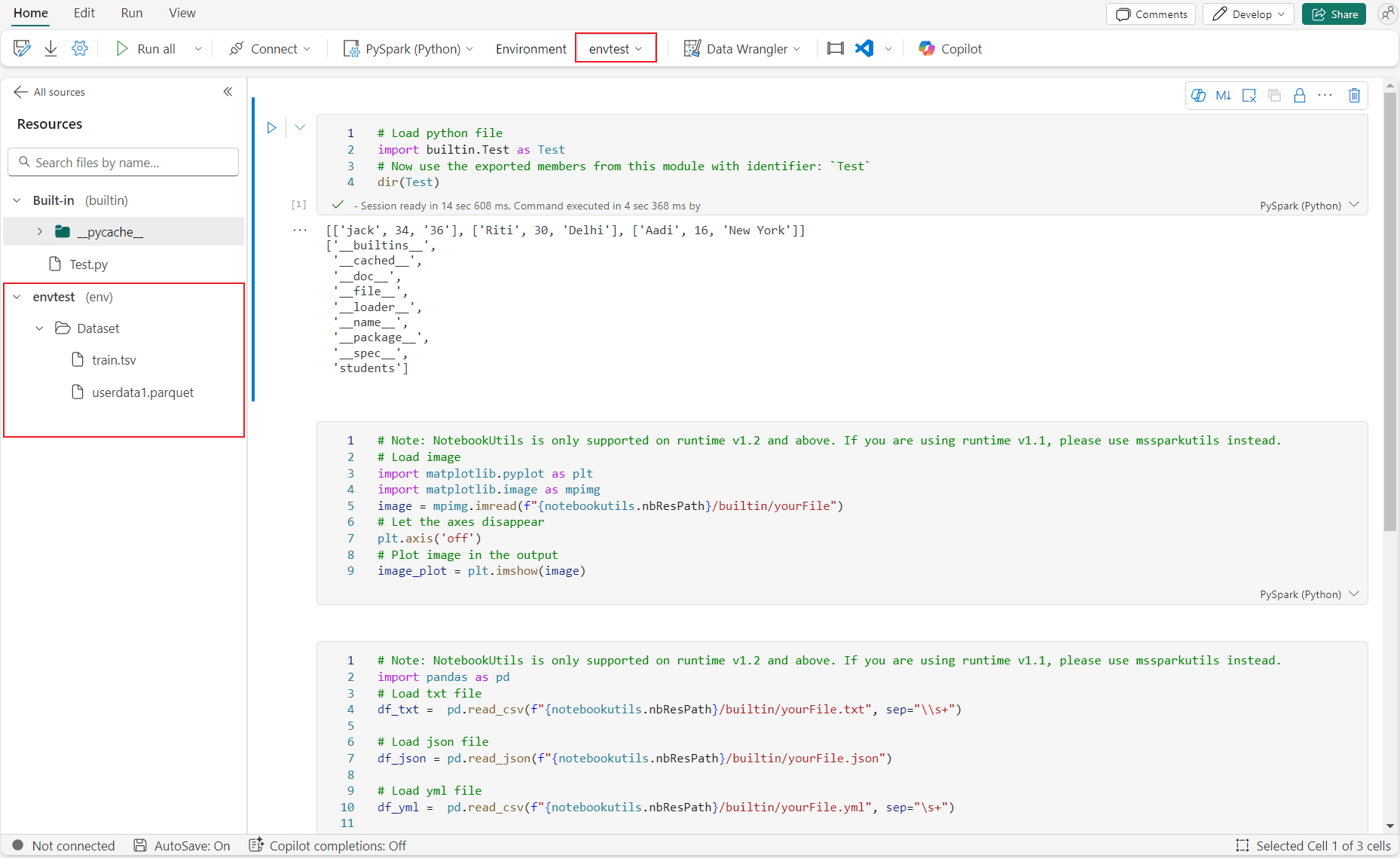
Credit: Microsoft
Decision guide: Dataflows Gen2 vs. Notebooks
Dimension | Dataflows Gen2 (Power Query) | Notebooks (Spark) |
|---|---|---|
Typical sources | SQL/relational, SaaS apps, OData/REST, CSV/Excel | Files in OneLake/ADLS, streaming, APIs via code, JDBC/ODBC |
Transformation style | Declarative, UI-driven; best when query folding pushes work to source | Programmatic; best when transformations can’t fold or require distributed compute |
Scale characteristics | Scales with capacity; parallel across queries/partitions but not cluster-distributed | Cluster-distributed across partitions; handles large joins, wide aggregations, and complex UDFs |
Incremental patterns | Built-in filters/parameters; source-pushed incremental loads when foldable | Programmatic CDC and merge patterns; robust file/table partitioning strategies |
Output targets | Lakehouse Tables (Delta); Lakehouse Files (preview); Warehouse | Delta tables in Lakehouse/OneLake; Fabric Warehouse via Spark connector |
Time to value | Fast for common patterns; business-friendly | Slower to build, faster to run at scale for heavy workloads |
Skills needed | Power Query/M, data modeling | Python/SQL/Scala, Spark concepts, data engineering |
Use this table as a heuristic, not a rule. Many teams mix both: Dataflows for source ingestion and simple transformations, Notebooks for heavy joins and curation into gold tables.
Are Dataflows still efficient for very large tables?
Yes—if you design for foldability and incremental processing. Dataflows Gen2 remain highly effective for large, structured facts and dimensions when:
The source can do the heavy lifting. With Power Query’s query folding, filters, projections, joins, and aggregations execute in the source database or warehouse. This keeps the dataflow job focused on movement and final shaping rather than compute.
Loads are incremental. Partition your loads by date/time or other natural keys. Refresh new/changed partitions only, not the full history. Done right, you process a small slice each run while leaving historical partitions untouched.
Transformations are “set-based,” not row-by-row. Avoid steps that break folding (e.g., complex custom functions on each row). Favour native operations that translate to T-SQL or the source dialect.
In practice, enterprises sustain large tables by pushing filters to the source (for example, last N days per run), splitting very large entities into partitions by period or domain and refreshing them in parallel, and landing into Delta tables in OneLake for predictable schema and downstream performance.
Where Dataflows struggle is when folding is impossible or when transformations require distributed compute. If critical steps don’t fold, Power Query must materialize and transform data in-engine; performance then depends on available capacity and may be subject to throttling, queueing, or timeouts.
When are Notebooks mandatory?
Choose Notebooks when any of the following apply:
Transformations can’t fold and are heavy. Large fact-to-fact joins, complex window functions, deduplication across billions of rows, or advanced aggregations benefit from Spark’s distributed execution.
Semi-structured or nested data at scale. Ingesting JSON with arrays/structs, XML, or log data that requires explode/flatten, schema inference, and schema drift handling.
File-centric or streaming patterns. Handling millions of small files, compacting and optimizing Delta tables, or ingesting micro-batches/streams using Structured Streaming with checkpointing to Lakehouse.
Advanced data engineering libraries. You need data quality libraries, feature engineering, or custom Python/Scala code for parsing, enrichment, or ML-adjacent prep.
Delta table maintenance. You want control over compaction, partitioning, stats, and housekeeping operations on large tables.
Cross-layer orchestration. Curating bronze to silver to gold with explicit checkpointing and idempotent merge logic.
For curated outputs that must land in a Warehouse, use the Spark connector from notebooks to write tables directly.
If you recognize these patterns, Notebooks (often orchestrated by Pipelines) provide the reliability and throughput you’ll need.
Implementation guide
Classify your sources and targets
Segment workloads by source type (relational vs. semi-structured), transformation complexity, and required latency. Decide whether the target is a Lakehouse table, Warehouse, or both.
Test for foldability early
Prototype and use folding indicators / query plan in Power Query to confirm which steps fold; if critical steps don’t fold, plan for a Notebook.
Design incremental strategy
Choose a partitioning key (e.g., ingestion date or business date). For Dataflows, filter on partitions at the source; for Notebooks, design Delta partition columns and idempotent merges.
Pilot both at realistic scale
Use representative volumes. Measure run time, CPU/memory, and OneLake I/O. Compare end-to-end cost and operational complexity. Avoid decisions based on toy datasets.
Formalise patterns and guardrails
Document when to use Dataflows vs. Notebooks, naming conventions, destinations, and monitoring. Embed these in templates so teams don’t reinvent the wheel.
Performance, capacity, and cost tactics
Dataflows Gen2. Maximise query folding and keep it until the last possible step. Push down filters and joins; pre-aggregate where acceptable. Partition and parallelise entities to use capacity efficiently. Land to Delta with sensible column types and avoid late type changes that force extra casts.
Notebooks (Spark). Read/write Delta with partitioning aligned to query filters, and avoid over-partitioning that creates tiny files. Control shuffle and file sizes by (re)partitioning before writes. Use idempotent merges with deterministic keys and checkpoints. Schedule compaction and housekeeping (OPTIMIZE/VACUUM) to keep performance predictable.
Both. Orchestrate with Pipelines for retries and dependencies so scheduling and alerting are centralised. Monitor capacity. Use the Fabric Capacity Metrics app and throttling guidance to detect contention; scale capacity or adjust concurrency and schedules accordingly.
Governance and security considerations
Use Fabric’s lineage view and monitoring hub to trace sources, transformations, and consumers across Dataflows and Notebooks. Apply workspace-level RBAC and item permissions consistently, and limit write access to curated layers (silver/gold). Prefer workspace identity authentication where supported, and Azure Key Vault references (preview) for data connections; avoid hard-coding secrets in Notebooks. Separate dev/test/prod workspaces and use Git integration (Dataflows Gen2) and Notebook source control to enable CI/CD with approvals. Define data contracts with owners, SLAs, and schema expectations per table. For Delta, plan column evolution and validate on write.
Common pitfalls
Assuming size alone dictates the engine; transformation profile and foldability matter more.
Breaking query folding early with convenience steps in Power Query, then blaming Dataflows for slowness.
Writing millions of tiny Delta files from Spark; fast to ingest, slow to use—plan compaction.
Mixing writers to the same Delta table without coordination can cause optimistic-concurrency conflicts; follow VACUUM retention guidance to avoid reader failures.
No incremental strategy; full reloads on big tables become infeasible and expensive.
Skipping monitoring/alerting; discovering failures days later when finance closes.
Over-customising before templating; every team solves the same problem a different way.
FAQs
Q: Are Dataflows Gen2 being replaced by Notebooks in Fabric?
A: No. They serve different purposes and coexist. Dataflows Gen2 are the fastest path for structured ingestion and ELT where query folding applies. Notebooks are for distributed data engineering, complex logic, and file-centric/streaming scenarios. Most mature Fabric estates use both.
Q: Can Dataflows handle “very large” tables?
A: Yes, when designed for foldability and incremental load. If the source can filter and aggregate, and you partition the load, Dataflows can efficiently keep large facts current. If your logic forces in-engine processing or requires big joins, you’ll likely need Notebooks for reliable throughput.
Q: When should I default to Notebooks?
A: Default to Notebooks when dealing with nested/JSON data, large fact-to-fact joins, deduplication across massive volumes, complex windowing, or when you need Spark libraries and explicit control over partitioning and Delta maintenance.
Q: Can we mix both on the same table?
A: You can, but coordinate carefully. Designate a single writer per table per layer (e.g., Dataflows produce bronze/silver; Notebooks curate silver/gold) and avoid concurrent writes. Use Pipelines for sequencing and enforce idempotency.
Q: How do we migrate a Dataflow to a Notebook?
A: There’s no one-click conversion. Translate Power Query logic (M) into Spark SQL or PySpark step by step, validating outputs. Use the migration to re-assess partitioning, joins, and Delta layout. Keep the old path until validation passes.
Q: What about licensing and capacity?
A: Both Dataflows and Notebooks consume Fabric capacity units (CUs). Throughput and cost depend on your capacity SKU and workload concurrency. Monitor consumption with the Capacity Metrics app to guide scheduling or scaling decisions.
Q: Do Dataflows support CDC?
A: They can implement incremental patterns if the source exposes change windows or change flags and the logic folds. For more advanced CDC (change data feeds, watermarking across multiple sources), Notebooks offer more control and repeatability.
Q: Can Notebooks write to Warehouses?
A: Yes, via connectors or by landing curated Delta in OneLake and exposing it through Lakehouse/Warehouse as appropriate. Choose the serving layer based on consumption needs and governance.
Glossary
Dataflows Gen2: Power Query–based data transformation in Fabric’s Data Factory experience, landing results into OneLake/Lakehouse/Warehouse.
Notebook: Interactive Spark environment in Fabric for Python/SQL/Scala/R data engineering and analytics.
OneLake: Fabric’s unified data lake, the storage foundation for Lakehouse and Warehouse.
Lakehouse: Fabric item combining a managed Delta data lake with SQL endpoints for analytics.
Warehouse: Fabric’s relational, SQL-native serving layer over managed storage.
Query folding: Power Query’s ability to push transformations back to the source system for execution.
Delta Lake: Open table format enabling ACID transactions, schema evolution, and time travel on data lakes.
Partitioning: Splitting data by a key (e.g., date) to improve load and query performance.
Incremental load: Loading only new or changed data instead of reprocessing the full dataset.
Orchestration: Scheduling and coordinating data jobs, dependencies, and retries, typically with Fabric Pipelines.
Closing
If you want a pragmatic blueprint for “Dataflows by default, Notebooks when needed,” we can help. CaseWhen designs Fabric patterns, capacity sizing, and governance guardrails so teams ship faster without future rework. Get a short assessment or a working template for your next large table ingestion and curation. Reach out via our contact page.
Related to Microsoft Fabric and Azure