
Microsoft Fabric und Azure
Verfasst von: Sajagan Thirugnanam und Austin Levine
Zuletzt aktualisiert am 2. Oktober 2025
Wenn Sie in einem mittelgroßen bis großen Unternehmen die Leitung im Bereich Daten oder Finanzen übernehmen, bietet Ihnen Fabric zwei gängige Methoden, um Daten in großem Maßstab zu übertragen und zu transformieren: Dataflows Gen2 (Power Query in der Fabric Data Factory-Umgebung) und Notebooks (Spark in der Data Engineering-Umgebung). Beide übertragen Daten in OneLake und können Lakehouse/Warehouse-Modelle unterstützen. Die praktische Frage ist weniger „Welche ist besser?“ und mehr „Welche ist für diese Arbeitslast richtig, und wann sollten wir wechseln?“
Schnelle Antwort: Verwenden Sie Dataflows Gen2 standardmäßig für strukturierte Quellen und ELT-Muster, bei denen Transformationen auf die Quelle heruntergeschoben werden können (Abfragefaltung) und bei denen inkrementelle Ladevorgänge die Belastung überschaubar halten. Verwenden Sie Notebooks, wenn Transformationen nicht gefaltet werden können, Sie verteilte Rechenleistung benötigen (große Joins/Aggregationen), mit verschachtelten Dateien oder Streaming arbeiten, erweiterte Daten-Engineering-Bibliotheken benötigen oder Delta-Level-Wartung in großem Umfang erforderlich ist.
Inhaltsverzeichnis
Wie es funktioniert
Leitfaden zur Entscheidung: Dataflows Gen2 versus Notebooks
Sind Dataflows immer noch effizient für sehr große Tabellen?
Wann sind Notebooks zwingend notwendig?
Implementierungsleitfaden
Leistungs-, Kapazitäts- und Kostentaktiken
Governance- und Sicherheitsüberlegungen
Häufige Fallstricke
FAQs
Glossar
Abschluss
Wie es funktioniert
Dataflows Gen2 führt Power Query in der Cloud aus, um Daten aus Hunderten von Quellen zu extrahieren und zu transformieren und dann das Ergebnis in Lakehouse-Tabellen (Delta), Lakehouse-Dateien (Vorschau) oder ein Fabric Warehouse zu übertragen. Ihre Stärke liegt in der Quellkonnektivität, Produktivität und der Fähigkeit, Arbeit über Abfragefaltung an das Quellsystem zurückzugeben. Sie laufen auf Ihrer Fabric-Kapazität und werden in der Data Factory-Umgebung orchestriert.
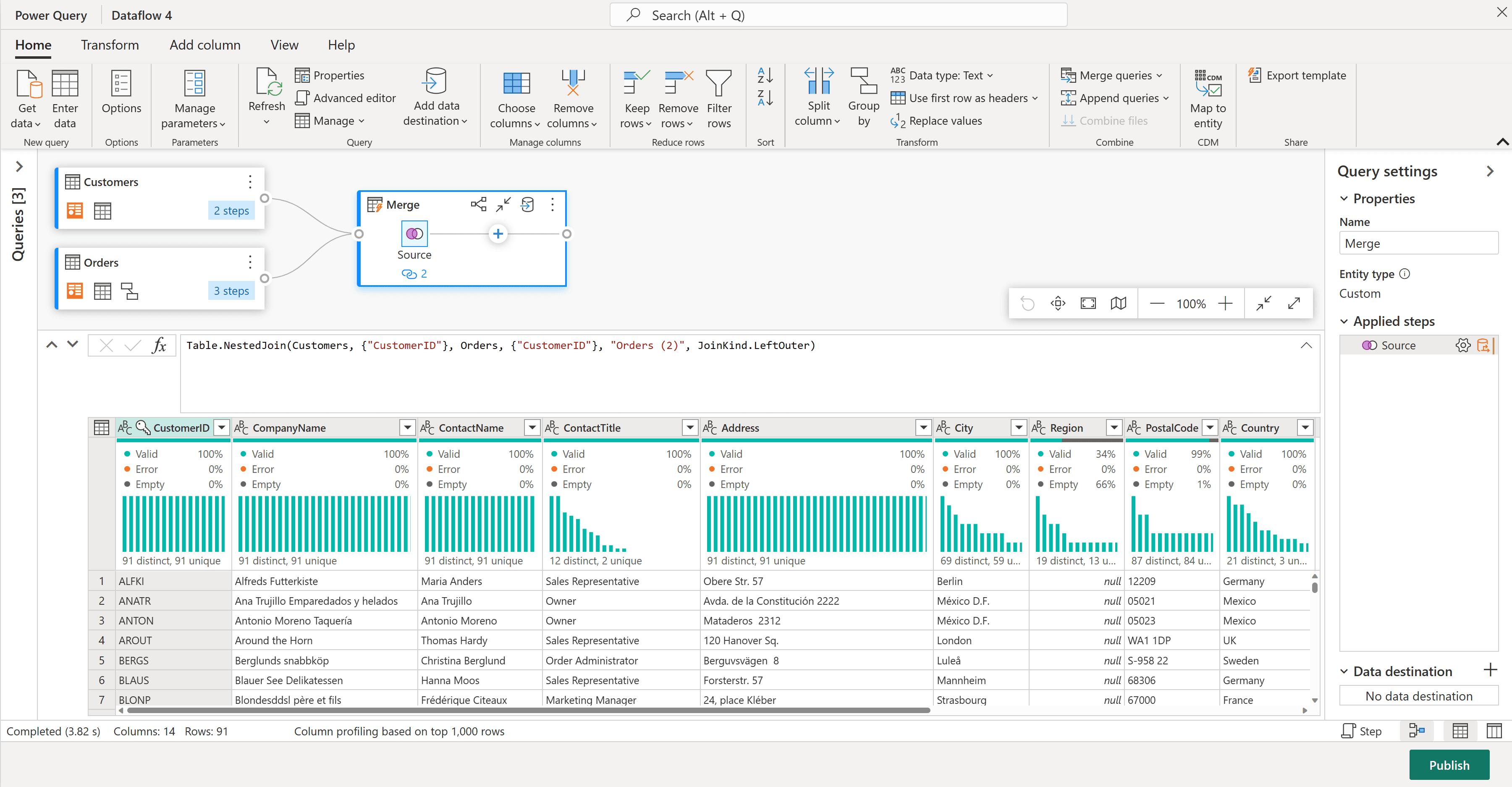
Bildnachweis: Microsoft
Notebooks in Fabric laufen auf verwaltetem Apache Spark. Sie schreiben Transformationen in Python (PySpark), Spark SQL, Scala oder R (SparkR) und arbeiten direkt mit Dateien und Delta-Tabellen in OneLake. Die Engine ist verteilt, sodass sich Joins, breite Aggregationen und komplexe Transformationen über den Spark-Cluster skalieren lassen. Notebooks decken auch Szenarien ab, die über reines ETL hinausgehen: Datenqualitäts-Frameworks, Feature Engineering und Streaming/Micro-Batch-Muster.
Bildnachweis: Microsoft
Leitfaden zur Entscheidung: Dataflows Gen2 versus Notebooks
Dimension | Dataflows Gen2 (Power Query) | Notebooks (Spark) |
|---|---|---|
Typische Quellen | SQL/relationale Systeme, SaaS-Anwendungen, OData/REST, CSV/Excel | Dateien in OneLake/ADLS, Streaming, APIs via Code, JDBC/ODBC |
Transformationsstil | Deklarativ, UI-gesteuert; am besten, wenn Abfragefaltung Arbeit auf die Quelle überträgt | Programmatisch; am besten, wenn Transformationen nicht gefaltet werden können oder verteiltes Rechnen erfordern |
Skalenmerkmale | Skaliert mit Kapazität; parallel über Abfragen/Partitionen, aber nicht cluster-verteilt | Cluster-verteilt über Partitionen; bewältigt große Joins, breite Aggregationen und komplexe UDFs |
Inkrementelle Muster | Eingebaute Filter/Parameter; quellengetriebene inkrementelle Ladevorgänge bei Faltbarkeit | Programmgesteuerte CDC- und Merge-Muster; robuste Datei-/Tabellenpartitionierungsstrategien |
Ziel-Outputs | Lakehouse-Tabellen (Delta); Lakehouse-Dateien (Vorschau); Warehouse | Delta-Tabellen in Lakehouse/OneLake; Fabric Warehouse über Spark-Connector |
Wertschöpfungszeit | Schnell für gängige Muster; geschäftsfreundlich | Langsamer zu erstellen, schneller bei großem Maßstab für schwere Arbeitslasten |
Benötigte Fähigkeiten | Power Query/M, Datenmodellierung | Python/SQL/Scala, Spark-Konzepte, Datenengineering |
Verwenden Sie diese Tabelle als Heuristik, nicht als Regel. Viele Teams mischen beide: Dataflows zur Quellaufnahme und einfachen Transformationen, Notebooks für schwere Joins und die Kuratierung in Goldtabellen.
Sind Dataflows immer noch effizient für sehr große Tabellen?
Ja—wenn Sie für die Faltbarkeit und die inkrementelle Verarbeitung entwerfen. Dataflows Gen2 bleiben hochwirksam für große, strukturierte Fakten und Dimensionen, wenn:
Die Quelle kann die schwere Arbeit übernehmen. Mit der Abfragefaltung von Power Query führen Filter, Projektionen, Joins und Aggregationen in der Quelldatenbank oder dem Warehouse ausgeführt. Dies hält den Dataflow-Job auf Bewegung und Endformung fokussiert, anstatt auf Berechnung.
Die Ladevorgänge sind inkrementell. Partitionieren Sie Ihre Ladevorgänge nach Datum/Uhrzeit oder anderen natürlichen Schlüsseln. Aktualisieren Sie nur neue/geänderte Partitionen, nicht die gesamte Historie. Richtig gemacht, verarbeiten Sie bei jedem Lauf einen kleinen Teil, während historische Partitionen unberührt bleiben.
Transformationen sind „satzbasiert“, nicht zeilenweise. Vermeiden Sie Schritte, die die Faltung brechen (z.B. komplexe benutzerdefinierte Funktionen in jeder Zeile). Bevorzugen Sie native Operationen, die in T-SQL oder den Quelldialekt übersetzt werden.
In der Praxis erhalten Unternehmen große Tabellen, indem sie Filter an die Quelle übertragen (z.B. letzte N Tage pro Lauf), sehr große Einheiten in Partitionen nach Zeitraum oder Domain aufteilen und parallel aktualisieren, und sie in Delta-Tabellen in OneLake ablegen für vorhersehbares Schema und Downstream-Leistung.
Wo Dataflows Schwierigkeiten haben, ist, wenn Falten unmöglich ist oder wenn Transformationen verteiltes Rechnen erfordern. Wenn kritische Schritte nicht gefaltet werden, muss Power Query Daten im Motormaterialisieren und transformieren; die Leistung hängt dann von der verfügbaren Kapazität ab und kann Drosselung, Warteschlangen oder Zeitlimits unterliegen.
Wann sind Notebooks zwingend notwendig?
Wählen Sie Notebooks, wenn eines der folgenden Kriterien zutrifft:
Transformationen können nicht gefaltet werden und sind schwer. Große Fakt-zu-Fakt Joins, komplexe Fensterfunktionen, Deduplizierung über Milliarden von Zeilen oder erweiterte Aggregationen profitieren von der verteilten Ausführung von Spark.
Semi-strukturierte oder verschachtelte Daten im großen Maßstab. Ingestieren von JSON mit Arrays/Strukturen, XML oder Log-Daten, die explode/flatten, Schemaerkennung und Schemaabweichung erfordern.
Dateizweckmäßige oder Streaming-Muster. Umgang mit Millionen kleiner Dateien, Kompaktierung und Optimierung von Delta-Tabellen oder Ingestieren von Mikrobatches/Streams unter Verwendung der strukturierten Streaming mit Checkpointing im Lakehouse.
Erweiterte Daten-Engineering-Bibliotheken. Sie benötigen Datenqualitätsbibliotheken, Feature Engineering oder benutzerdefinierten Python/Scala-Code zur Analyse, Anreicherung oder Vorbereitung im ML-Bereich.
Delta-Tabellen-Wartung. Sie möchten Kontrolle über Kompaktierung, Partitionierung, Statistiken und Pflegeoperationen auf großen Tabellen.
Orchestrierung über mehrere Schichten. Kuratierung von Bronze zu Silber zu Gold mit explizitem Transaction Logging und idempotenter Merge-Logik.
Für kuratierte Outputs, die in einem Warehouse landen müssen, verwenden Sie den Spark-Connector von Notebooks, um Tabellen direkt zu schreiben.
Wenn Sie diese Muster erkennen, bieten Notebooks (oft von Pipelines orchestriert) die Zuverlässigkeit und den Durchsatz, den Sie benötigen.
Implementierungsleitfaden
Klassifizieren Sie Ihre Quellen und Ziele
Segmentieren Sie Arbeitslasten nach Quelltyp (relational versus semi-strukturiert), Transformationskomplexität und erforderlicher Latenzzeit. Entscheiden Sie, ob das Ziel eine Lakehouse-Tabelle, ein Warehouse oder beides ist.
Testen Sie frühzeitig auf Faltbarkeit
Prototypisieren und verwenden Sie Falteindikatoren/Abfragepläne in Power Query, um zu bestätigen, welche Schritte gefaltet werden; wenn kritische Schritte nicht gefaltet werden, planen Sie ein Notebook.
Entwerfen Sie eine inkrementelle Strategie
Wählen Sie einen Partitionierungsschlüssel (z.B. Ingestierungsdatum oder Geschäftsdaten). Bei Dataflows filtern Sie auf Partitionen in der Quelle; bei Notebooks entwerfen Sie Delta-Partitionierungsspalten und idempotente Merges.
Pilotieren Sie beide in realistischer Skalierung
Verwenden Sie repräsentative Volumina. Messen Sie die Laufzeit, CPU/RAM und OneLake-I/O. Vergleichen Sie die End-to-End-Kosten und die betriebliche Komplexität. Vermeiden Sie Entscheidungen auf der Grundlage von Spielzeug-Datensätzen.
Formalisieren Sie Muster und Leitplanken
Dokumentieren Sie, wann Dataflows oder Notebooks verwendet werden sollen, Namenskonventionen, Ziele und Überwachung. Betten Sie diese in Vorlagen ein, damit Teams nicht das Rad neu erfinden.
Leistungs-, Kapazitäts- und Kostentaktiken
Dataflows Gen2. Maximieren Sie die Abfragefaltung und halten Sie sie bis zum letzten möglichen Schritt. Filters und Joins herunterschieben; voraggregieren, wo akzeptabel. Partitionieren und parallelisieren Sie Entitäten, um die Kapazität effizient zu nutzen. Landen Sie in Delta mit sinnvollen Spaltentypen und vermeiden Sie späte Typänderungen, die zusätzliche Umwandlungen erzwingen.
Notebooks (Spark). Lesen/Schreiben Sie Delta mit Partitionierung, die auf Abfragefilter abgestimmt ist, und vermeiden Sie Überpartitionierung, die winzige Dateien erstellt. Kontrollieren Sie Shuffle- und Dateigrößen, indem Sie vor dem Schreiben (um-)partitionieren. Verwenden Sie idempotente Merges mit deterministischen Schlüsseln und Checkpoints. Planen Sie Kompaktierung und Pflege (OPTIMIZE/VACUUM) ein, um die Leistung vorhersehbar zu halten.
Beide. Orchestrieren Sie mit Pipelines für Wiederholungen und Abhängigkeiten, sodass Planung und Benachrichtigung zentralisiert sind. Überwachen Sie die Kapazität. Verwenden Sie die Fabric Capacity Metrics App und Drosselrichtlinien, um Engpässe zu erkennen; passen Sie Kapazität oder Zeitpläne dementsprechend an.
Governance- und Sicherheitsüberlegungen
Verwenden Sie die Fabric-Linienansicht und den Überwachungshub, um Quellen, Transformationen und Verbraucher über Dataflows und Notebooks hinweg zu verfolgen. Wenden Sie durchgängiges RBAC auf Arbeitsbereichebene und Elementberechtigungen an und beschränken Sie den Schreibzugriff auf kuratierte Ebenen (Silber/Gold). Bevorzugen Sie Identitätsauthentifizierung von Arbeitsbereichen, wo unterstützt, und Azure Key Vault-Referenzen (Vorschau) für Datenverbindungen; vermeiden Sie fest codierte Geheimnisse in Notebooks. Trennen Sie Entwicklungs-/Test-/Produktionsarbeitsbereiche und nutzen Sie Git-Integration (Dataflows Gen2) und Notebook-Quellcodekontrolle zur Implementierung von CI/CD mit Genehmigungen. Definieren Sie Datenverträge mit Eigentümern, SLAs und Schemavorerwartungen pro Tabelle. Für Delta planen Sie Spaltenerweiterungen und validieren Sie beim Schreiben.
Häufige Fallstricke
Annehmen, die Größe allein bestimme die Engine; Transformationsprofil und Faltbarkeit sind wichtiger.
Frühes Brechen von Abfragefaltung mit bequemeren Schritten in Power Query und dann Dataflows für Langsamkeit verantwortlich machen.
Schreiben von Millionen winziger Delta-Dateien aus Spark; schnell zu ingestieren, langsam zu verwenden—Planen Sie Kompaktierung.
Mixing von Autoren zur selben Delta-Tabelle ohne Koordination kann zu Optimistic Concurrency-Konflikten führen; folgen Sie den VACUUM-Aufbewahrungsrichtlinien, um Leserfehler zu vermeiden.
Keine inkrementelle Strategie; vollständige Neuladungen auf großen Tabellen werden unpraktikabel und teuer.
Überwachungs-/Alarmierung überspringen; Fehler erst Tage später entdecken, wenn das Finanzbuch geschlossen wird.
Übermäßiges Anpassen vor der Erstellung von Vorlagen; jedes Team löst dasselbe Problem auf unterschiedliche Weise.
FAQs
Q: Werden Dataflows Gen2 von Notebooks in Fabric ersetzt?
A: Nein. Sie dienen unterschiedlichen Zwecken und koexistieren. Dataflows Gen2 sind der schnellste Weg für strukturierte Ingestierung und ELT, wenn Abfragefaltung anwendbar ist. Notebooks sind für verteilt ausgeführte Daten-Engineering, komplexe Logik und dateizentrierte/Streaming-Szenarien. Die meisten ausgereiften Fabric-Installationen verwenden beide.
Q: Können Dataflows „sehr große“ Tabellen verarbeiten?
A: Ja, wenn sie für Faltbarkeit und inkrementelles Laden entwickelt wurden. Wenn die Quelle filtern und aggregieren kann und Sie den Ladevorgang partitionieren, können Dataflows effizient große Fakten aktuell halten. Wenn Ihre Logik eine interne Verarbeitung erzwingt oder große Joins erfordert, benötigen Sie wahrscheinlich Notebooks für einen zuverlässigen Durchsatz.
Q: Wann sollte ich standardmäßig Notebooks verwenden?
A: Standardmäßig Notebooks verwenden, wenn Sie mit verschachtelten/JSON-Daten, großen Fakt-zu-Fakt-Joins, Deduplizierung über massive Volumen, komplexem Marginalien oder wenn Sie Spark-Bibliotheken und explizite Kontrolle über Partitionierung und Delta-Wartung benötigen.
Q: Können wir beide für dieselbe Tabelle mischen?
A: Sie können, aber koordinieren Sie sorgfältig. Bestimmen Sie einen einzigen Autor pro Tabelle pro Schicht (z.B. Dataflows erstellen Bronze/Silber; Notebooks kuratieren Silber/Gold) und vermeiden Sie gleichzeitiges Schreiben. Verwenden Sie Pipelines für die Sequenzierung und erzwingen Sie Idempotenz.
Q: Wie migrieren wir einen Dataflow zu einem Notebook?
A: Es gibt keine Ein-Klick-Anpassung. Übersetzen Sie die Power Query-Logik (M) schrittweise in Spark SQL oder PySpark und validieren Sie die Ausgaben. Verwenden Sie die Migration, um eine Neubewertung der Partitionierung, Joins und Delta-Layouts durchzuführen. Halten Sie den alten Pfad, bis die Validierung bestanden ist.
Q: Was ist mit Lizenzierung und Kapazität?
A: Sowohl Dataflows als auch Notebooks verbrauchen Fabric Kapazitätseinheiten (CUs). Durchsatz und Kosten hängen von Ihrem Kapazitäts-SKU und Arbeitslastkonkurrenz ab. Überwachen Sie den Verbrauch mit der Capacity Metrics App, um die Planung oder Skalierungsentscheidungen zu leiten.
Q: Unterstützen Dataflows CDC?
A: Sie können inkrementelle Muster implementieren, wenn die Quelle Änderungensfenster oder Änderungsflaggen enthüllt und die Logik gefaltet wird. Für erweiterte CDC (Änderungsdaten-Feeds, Wasserzeichen über mehrere Quellen), bieten Notebooks mehr Kontrollmöglichkeiten und Wiederholbarkeit.
Q: Können Notebooks in Warehouses schreiben?
A: Ja, über Konnektoren oder indem sie kuratierte Delta in OneLake landen und sie durch Lakehouse/Warehouse verfügbar machen, je nach Verbrauchsbedürfnis und Governance.
Glossar
Dataflows Gen2: Power Query-basierte Datentransformation in Fabrics Data Factory-Erfahrung, Ablage der Ergebnisse in OneLake/Lakehouse/Warehouse.
Notebook: Interaktive Spark-Umgebung in Fabric für Python/SQL/Scala/R-Datenengineering und -analysen.
OneLake: Fabrics vereinheitlichtes Data Lake, das Speicherfundament für Lakehouse und Warehouse.
Lakehouse: Fabric-Item, das einen verwalteten Delta Data Lake mit SQL-Endpunkten für Analysen kombiniert.
Warehouse: Fabrics relationales, SQL-natives Dienstmodul über verwaltetem Speicher.
Abfragefaltung: Die Fähigkeit von Power Query, Transformationen zur Ausführung an das Quellsystem zurückzugeben.
Delta Lake: Offenes Tabellenschema, das ACID-Transaktionen, Schemaentwicklung und Zeitreisen auf Data Lakes ermöglicht.
Partitionierung: Das Aufteilen von Daten nach einem Schlüssel (z.B. Datum), um die Lade- und Abfrageleistung zu verbessern.
Inkrementelles Laden: Nur neue oder geänderte Daten laden, anstatt den gesamten Datensatz erneut zu verarbeiten.
Orchestrierung: Planung und Koordinierung von Datenjobs, Abhängigkeiten und Wiederholungen, typischerweise mit Fabric Pipelines.
Abschluss
Wenn Sie einen pragmatischen Plan für „Dataflows standardmäßig, Notebooks bei Bedarf“ suchen, können wir helfen. CaseWhen entwirft Fabric-Muster, Kapazitätsplanungen und Governance-Leitplanken, sodass Teams schneller liefern können, ohne Nacharbeiten in der Zukunft. Erhalten Sie eine kurze Bewertung oder eine funktionierende Vorlage für Ihre nächste großvolumige Tabellenübertragung und -kuratierung. Kontaktieren Sie uns über unsere Kontaktseite.
Bezogen auf Microsoft Fabric und Azure